Introduction
- Introduction
- The Agent-Environment Interface
- Markov Decision Process
- Value Function
- Action-Value Function
- VI vs. PI
- Asynchronous Dynamic Programming
The Agent-Environment Interface
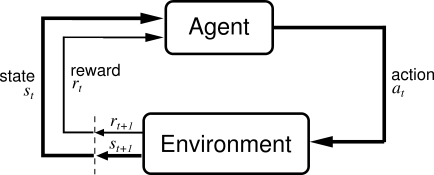
Markov Decision Process

-
Because of the Markov property, the optimal policy for this particular problem can indeed be written as a function of s only, as assumed above.
-
Markov Reward Process (MRP) = MDP + a fixed policy

Value Function


Action-Value Function



VI vs. PI
- VI is PI with one step of policy evaluation.
- PI converges surprisingly rapidly, however with expensive computation, i.e. the policy evaluation step (wait for convergence of V^π).
- PI is preferred if the action set is large.
Asynchronous Dynamic Programming
- The value function table is updated asynchronously.
- Computation is significantly reduced.
- If all states are updated infinitely, convergence is still guaranteed.
- Three simple algorithms:
- Gauss-Seidel Value Iteration
- Real-time dynamic programming
- Prioritised sweeping



